
I spent some time last week working on another project to add to my portfolio. This project, building a predictive model for loan approvals, is listed as the third beginner level project in this guide and I thought it would be straightforward.
Following the typical data cleanup tasks, my initial plan was to compare three basic predictive models:
- Logistic Regression
- Decision Tree
- Random Forest
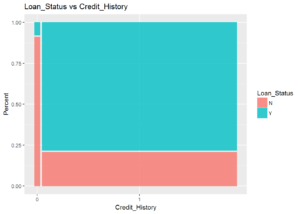
Initial exploration of the data showed that the applicant’s credit history has the largest single-variable influence on the loan approval. Other variables that seem important are: marital status, education level, and property area. Having made these discoveries, I was ready to jump into training the models.
Because the credit history appears to have such a strong correlation with loan approval, a model using credit history as a predictor was also used. When the results from this model was submitted to the competition it received a score of 78%.
Next I trained the logistic regression model. It turns out that the only variable of any significance is the credit history. Submitting the results of this model again obtains a score of 78% accuracy.
Okay, moving on to the decision tree model. Decision trees are easy to over-fit, and so I didn’t want to include all the variables. Starting with the variables I determined to have the most impact, I trained the decision tree model and found that the optimal decision tree model looks like the one shown below:
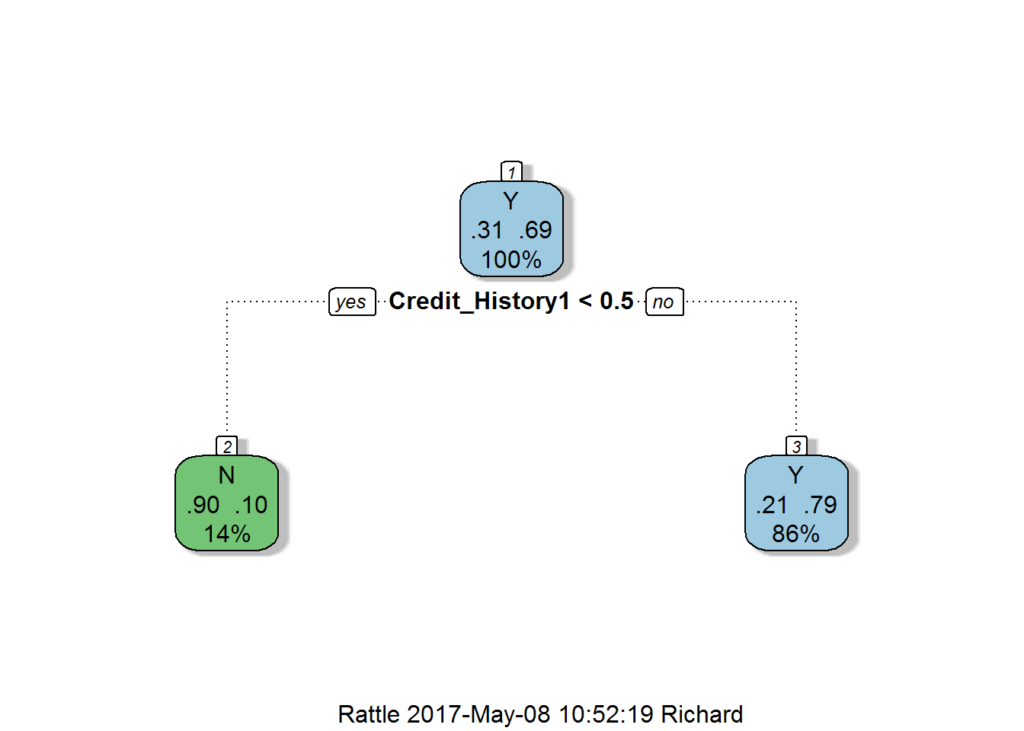
At this point, I’m really wondering what I’m doing wrong. I break down and look at the tutorial. At first glance, the tutorial isn’t helpful. They don’t do better, and the included random forest model doesn’t get much better accuracy than the original logistic regression model that only uses the credit history.
So none of the basic models seem to work very well. Why is this a beginner project? Keep in mind, this is the 3rd beginner project. By this point, its assumed the student is able to run the models. It’s only natural that the difficulty increases. The tutorial concludes with 3 important points:
- Using a more sophisticated model does not guarantee better results.
- Avoid using complex modeling techniques as a black box without understanding the underlying concepts. Doing so would increase the tendency of overfitting thus making your models less interpretable
- Feature Engineering is the key to success. Everyone can use an Xgboost models but the real art and creativity lies in enhancing your features to better suit the model.
Looking at the competition leaderboard, the top submissions have an 83% accuracy rate, so improvements can be made. Time to dive into the data again and see what can be done.